IT 116: Introduction to Scripting
Class 26
Tips and Examples
Review
New Material
Microphone
Questions
Are there any questions before I begin?
Readings
If you have the textbook you should read Chapter 8,
More About Strings, from
Starting Out with Python.
Final Exam
The final exam will be held on Tuesday, December 16th from
3:00 - 6:00 PM.
The exam will be given in this room.
If for some reason you are not able to take the Final at the time it will
be offered, you MUST send an email to me before the exam
so we can make alternative arrangements.
The final will consist of questions taken from the Weekly Graded Quizzes, along
with questions asking you to write short segments of Python code.
There is a link to the answers to the graded quizzes on the class web page.
60% of the points on this exam will consist of questions from the Graded
Quizzes.
You do not need to study a Graded Quiz question if the topic is not
mentioned in either the Midterm or Final review.
The remaining 40% will come from 4 questions that ask you to write
some code.
To study for the code questions you should be able to
- Write a function to create a list from a file
- Write a function that changes the entries in a list
- Write a function that performs a calculation using the
elements of a list
- Write a function performs a calculation on the characters
in a string
A good way to study for the code questions is to review the Class Exercises,
homework solutions and Class Notes.
The last class on Thursday, December 11th, will be a review session.
You will only be responsible for the material in that review session,
which you will find here,
and the review for the Midterm, which you will find
here.
Although the time alloted for the exam is 3 hours, I would
expect that most of you would not need that much time.
The final is a closed book exam.
To prevent cheating, certain
rules
will be enforced during the exam.
Remember, the Midterm and Final determine 50% of your grade.
Course Evaluation
At the end of each semester we offer you the opportunity
to say what you think about this course.
What have I done right?
What have I done wrong?
What can I do better?
You are not asked for you name.
So the submissions are anonymous.
I will not see your responses until after I have submitted grades
for this course.
We collect this feedback through Course Evaluations.
I will use what you say to make this course better.
To complete the course evaluation, use the following
link
.
Quiz 10
Let's review the answers to
Quiz 10.
No Graded Quiz Next Week
Quiz 10 was the last graded quiz.
Don't forget the Linix InstallFest this coming Saturday, May 3rd,
from 9 to 5 in the McCormack Conference Room M03-0721.
Tips and Examples
A Practical Example of Reading File into Sequence Object
- Last class I talked about processing a file ...
- and creating a list
- Today I want to give you an example of reading a file into another sequence object
- A string
- At the start of each semester I need to collect data on all IT students
- Nowadays this data is stored in a Sqlite database
- But originally it was stored in a tuple of tuples
- Each class was a tuple of entries for each student
- The student entries were themselves tuples
- The student tuples containing the following
- Student ID
- First name
- Last name
- UMB email
- I get an Excel file from the Registrar with this information
- I export this file as a CSV text file
- In the CSV format the field values are separated by commas
Program Status Code,Term Code,Academic Career Code,Person ID,Person Name,First Name,Last Name,Program Code,Plan Code,Student Email Address,Personal Email Address
AC,2610,UGRD,01459837,"Smith,John",John,Smith,CSM-U,IT-BS,John.Smith001@umb.edu,jsmith@gmail.com
AC,2610,UGRD,01636476,"Jacobs,Jane",Jane,Jacobs,CSM-U,IT-BS,Jane.Jacobs002@umb.edu,jjacobs@gmail.com
AC,2610,UGRD,01523746,"Miller,Alan",Alan,Miller,CSM-U,IT-BS,Alan.Miller001@umb.edu,amiller@gmail.com
...
- This is not the real file
- I can't show that to you because of confidentiality rules
- My code uses split to break up the line into a list
- split needs to know what separates the individual
field values
- The characters between field values are called
delimiters
- If you run split with no argument it uses
spaces as the delimiter
- But that won't work with this file
- Here the delimiter is a comma, ,
- To use another delimiter you have to give split an argument
- That argument must be a string
- In the script I use "," as the argument
- I can then use indexing to get the values I need
- Here is the code
#! /usr/bin/python3
# takes a CSV file from the Registrar and turns it into
# a string representing tuples of the form
# (STUDENT_ID, FIRST_NAME, LAST_NAME, UMB_EMAIL)
# takes a string, strips it of whitespace, quotes it and adds a comma
def quote_comma(string):
return '"' + string.strip() + '", '
in_filename = input("Input filename: ")
in_file = open(in_filename, "r")
tuple = "" # creating a string repesenting the tuple which I will copy into a Python module
in_file.readline # skip first line with labels
for line in in_file:
line = line.strip()
fields = line.split(",")
tuple += "(" # create a string represnting a tuple for each student
id = fields[3]
first_name = fields[6]
last_name = fields[7]
umb_email = fields[10]
tuple += quote_comma(id) + quote_comma(first_name) + quote_comma(last_name) + umb_email
tuple += "),\n"
print(tuple)
- When I run it I get
("01459837", "John", "Smith", John.Smith001@umb.edu),
("01636476", "Jane", "Jacobs", Jane.Jacobs002@umb.edu),
("01523746", "Alan", "Miller", Alan.Miller001@umb.edu),
...
- I can copy this text into a Python tuple for all IT students
Review
List Elements
- The
elements
of a list can be anything
>>> list_1 = [1 , 2.5, True, "foo"]
>>> for element in list_1:
... print(element, type(element))))
...
1 <class 'int'>
2.5 <class 'float'>
True <class 'bool'>
foo <class 'str'>
- The elements of a list can even be another list
>>> list_2 = [ 1, 2, 3, 4, [5, 6, 7,]]
>>> for element in list_2:
... print(element, type(element))
...
1 <class 'int'>
2 <class 'int'>
3 <class 'int'>
4 <class 'int'>
[5, 6, 7] <class 'list'>
Two-Dimensional Lists
- When the elements of a list are lists, we have a
two-dimensional list
>>> tdl = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> tdl
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
- Each element of tdl is also a list
>>> for element in tdl:
... print(element)
...
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
- We can use indexing to get each sublist
>>> tdl[0]
[1, 2, 3]
>>> tdl[1]
[4, 5, 6]
>>> tdl[2]
[7, 8, 9]
- How do we get each element within the sublist?
- With another [ ]
>>> tdl[0][0]
1
>>> tdl[0][1]
2
>>> tdl[0][2]
3
Tuples
- A tuple
is a sequence of values that cannot be changed
- You create a tuple
literal
using parentheses, ( )
- They enclose a comma separated list of values
>>> tuple_1 = (1, 2, 3, 4, 5)
>>> tuple_1
(1, 2, 3, 4, 5)
- Tuples can contain elements of any type
>>> tuple_2 = (1, 2.5, False, "Sam")
>>> tuple_2
(1, 2.5, False, 'Sam')
- You can access the elements of a tuple with an index
>>> tuple_1[0]
1
- You can use a
for loop to print all the elements
>>> for number in tuple_1:
... print(number)
...
1
2
3
4
5
The tuple Conversion Function
- Each of the basic data types in Python has a conversion function
- The conversion function for tuples is
tuple
- It will work on strings
>>> name = "Glenn"
>>> tuple(name)
('G', 'l', 'e', 'n', 'n')
- And lists
>>> digits = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
>>> tuple(digits)
(1, 2, 3, 4, 5, 6, 7, 8, 9, 0)
- The argument to
tuple must be
iterable
- In other words, anything that can be used in a
for loop
Why Use Tuples?
- Lists and tuples are similar
- But tuples have many limitations
- So why should we use tuples?
- For security, among other things
- Tuples cannot be changed
- So any data you put in a tuple cannot be modified or corrupted
Attendance
New Material
Strings Are Sequences
- There are many different
data types
in Python
- Some hold only one value
- Other data types hold more than one value
- A
sequence
is a family of data types containing many values
- The values are stored one right after the other
- We have spent the last few classes talking about two sequence data types
- But
strings
are also sequences
- Strings are sequences where the elements are individual characters
- Strings are objects
- And they have methods
that work on the characters they contain
Accessing Characters With Indexing
- The characters in a string have a definite order
- This means we can use indexing to get a particular character
- If we have a string
>>> team = "Red Sox"

- We can use the [ ] operator to get a specific
character
- Inside the brackets we place an integer
>>> team[0]
'R'
- We can also use a variable as an index
>>> num = 4
>>> team[num]
'S'
- Or a calculation using
operators
>>> team[num +1]
'o'
- Or a
function call
that returns an integer
>>> team[len(team) - 1]
'x'
- Notice that I had to subtract 1 from the length of the string
- If I did not do this I would get an exception
>>> team[len(team)]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
Negative Numbers as Indexes
- You can't use any number as an index
- It must be an integer
- And it cannot be longer than the length of the list minus 1
>>> letters = "abcde"
>>> len(letters)
5
>>> letters[4]
'e'
>>> letters[5]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
- You might think that using a negative number as an index ...
- would raise an exception
- But you would be wrong
>>> letters
'abcde'
>>> letters[-1]
'e'
- A negative index is added to the length of the string
- In practices this means that -1 is the index of the last character
- -2 is the index of the second from last
- And so on
>>> letters[-1]
'e'
>>> letters[-2]
'd'
>>> letters[-3]
'c'
>>> letters[-4]
'b'
>>> letters[-5]
'a'
>>> letters[-len(letters)]
'a'
- This feature can be useful
- After all its easier to write
letters[-1]
- Than to write
letters[len(team) - 1]
- They are particularly useful with strings of different lengths
- You can always get the last character in the string using -1 as the index
- Negative index values can be used with any sequence
- They can be used with lists
>>> numbers = [1, 2, 3, 4, 5]
>>> numbers[-1]
5
- And with tuples
>>> values = (1, 2, 3, 4, 5)
>>> values[-1]
5
Using a for Loop with Strings
- A
for loop can be used with strings
>>> for ch in team:
... print(ch)
...
R
e
d
S
o
x
- This allows us to write some interesting functions
- We can count the number of times a certain character ...
- occurs in a string
>>> def character_count(string, char):
... count = 0
... for ch in string:
... if ch == char:
... count += 1
... return count
...
>>> character_count("Mississippi", "i")
4
>>> character_count("Mississippi", "s")
4
>>> character_count("Mississippi", "p")
2
- We can also use a
for loop to reverse a string
>>> def string_reverse(string):
... new_string = ""
... for ch in string:
... new_string = ch + new_string
... return new_string
...
>>> string_reverse("Mississippi")
'ippississiM'
>>> string_reverse("radar")
'radar'
- I first created an empty string
- Then added each character in the original string
- Notice that the new character comes before the string I'm building
- To better see how this works ...
- let's print out the changing value of
new_string ...
- inside the
for loop
>>> def string_reverse(string):
... new_string = ""
... for ch in string:
... new_string = ch + new_string
... print(new_string)
... return new_string
...
>>> string_reverse("Mississippi")
M
iM
siM
ssiM
issiM
sissiM
ssissiM
ississiM
pississiM
ppississiM
ippississiM
'ippississiM'
Strings Are Immutable
- Why did I write the function string_reverse
- Surely I could have used the reverse method of the
string object
- The graphic below lists the string methods
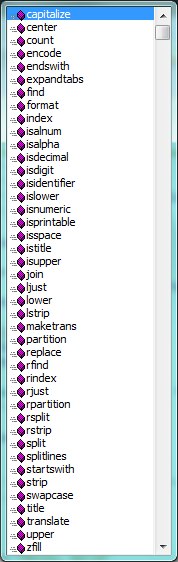

Garbage Collection
- But I can only work with the latest one
- If I keep doing this I would run out of memory
- If the program were written in C it would crash
- This is a type of bug called a "memory leak"
- Of course memory cannot leak away
- But if you keep creating new objects ...
- you will eventually run out of memory the script needs to run
- This does not happen in Python and most scripting languages
- It also does not happen in Java
- In these languages the interpreter does something called
garbage collection
- I works like this
- The interpreter keeps a table of all objects in memory ...
- and the variables that point to them
- Every so often the interpreter looks at this table
- It will then delete objects that have no variable pointing to them
- So programs written in Python will never have a memory leak
String Slicing
- A string that is contained inside another string is called a
substring
- Many languages have functions to extract a substring
- But Python gives us an easier way
- We can use slices
- Slicing works with all sequence objects
- Including strings
- So if we have the following string
>>> team = "Boston Red Sox"
- We can use a slice to extract the city from the larger string
>>> team[0:6]
'Boston'
- To create the slice I had to count to find where the substring ends
- But the index method of a string object can do that
work for us
>>> team.index(" ")
6
- We can use this function call in the slice
team[0:team.index(" ")]
'Boston'
- We are starting the slice at the beginning of the string
- So we can omit the 0
>>> team[:team.index(" ")]
'Boston'
- We can use this technique to split a full name into first and last names
- To do this we will assume that a full name consists of two names
- And that the names have no spaces inside them
>>> def first_name(full_name):
... return full_name[:full_name.index(" ")]
...
>>> first_name("Glenn Hoffman")
'Glenn'
>>> def last_name(full_name):
... return full_name[full_name.index(" ") + 1:]
...
>>> last_name("Glenn Hoffman")
'Hoffman'
Writing Programs Work with Words
- The first computers were created to do numerical calculations
- But people soon learned that they could also be used with words
- Think of the Big Five in Tech today
- Apple
- Google
- Amazon
- Microsoft
- Facebook
- Almost all of their products work with words
- Not numbers
- I will give some examples below
String Programs 1 - Turning Numbers into Words
- My first example is somewhat silly
- I want to write a program that turns an integer into words
- So 512 would become "five one two"
- To do this we need a way to turn a digit into its appropriate word
- This can be done by creating a list of the names of digits
- We can use the integer value of each digit ...
- as an index to get the word for that digit
- But we have to be smart about doing this
- If we defined the list like this
digits = ["one", "two", "three", ...
- The index of the word "one" would be 0
- So let's start the list with "zero"
>>> digits = ["zero", "one", "two", "three", "four"]
>>> digits += ["five", "six", "seven", "eight", "nine"]
- Let's iterate through this list using a
for loop
>>> for i in range(len(digits)):
... print(str(i) + ":\t" + digits[i])
...
0: zero
1: one
2: two
3: three
4: four
5: five
6: six
7: seven
8: eight
9: nine
- Here is the code
>>> def digits_to_words(number):
... new_string = ""
... number_string = str(number)
... for digit in number_string:
... digit = int(digit)
... new_string += digits[digit] + " "
... return new_string
...
>>> digits_to_words(512)
'five one two '
>>> digits_to_words(10428)
'one zero four two eight '
- We start with the empty string
- Then we turn the integer into a string
- We need to do this so we can use it in a
for loop
- Now we iterate through this string ...
- and turn each character back into an integer ...
- which we use as the index to digits
- This will give us the name of each digit
- We build the result by adding a space after each digit name
String Programs 2 - Checking for Anagrams
- Let's write a program to see if one string is an anagram of another
- An anagram is "a word, phrase, or name formed by rearranging the letters of
another"
- To make this problem easier we will only deal with words
- Not phrases
- Phrases have spaces in them which makes things more complicated
- A word is an anagram of another ...
- if they have the same letters ...
- but in a different order
- First we need to make sure the strings have the same length
- Then check that each character in the first word ...
- also appears in the second
- But this is not enough
- What if a character appears twice in the first word
- But only once in the second?
- A better idea is to loop through the characters in the first word
- And remove each character in the first from the second
- Here is the algorithm
if two words do not have the same length:
return False
for each character in word 1:
if that character is not in word 2:
return False
else
remove the character from word 2
return True
- Looks good but there is one problem
- How do we remove a character from a string when strings are immutable?
- The answer is to use the
list conversion function
- Then we can use the list method pop
- Here is the code
def is_anagram(word_1, word_2):
if len(word_1) != len(word_2):
return False
word_2 = list(word_2) # turn into list so we can use pop
for ch1 in word_1:
if ch1 not in word_2:
return False
ch2_index = word_2.index(ch1)
word_2.pop(ch2_index)
return True
- Let's test it
is_anagram("looped","poodle")
True
String Programs 3 - Creating Phony Student IDs
- I have created many scripts to automate much of my work
- I use some of these scripts as examples for this class
- A lot of these scripts deal with student data
- But I can't show you the real files my scripts work on
- That would be a violation of student confidentiality
- Creating phony names and email addresses is not hard
- But I also need phony student IDs
- I could make them up
- But its easier for me to run a script that does it for me
- A student ID has 8 digits
- And the first digit is always 0
- So you might think that I would use the following algorithm
set a string to "0"
for seven times
add a randomly selected digit to the end of the string
- But that is not what I did
- I found a simpler approach
- randrange from the
random module ...
- will return a pseudo random number between its two arguments
- I need a 7 digit number so I call the function as follows
>>> random.randrange(1000000,10000000)
3414599
- But I need a string ...
- so I will convert the number using
str
>>> str(random.randrange(1000000,10000000))
'1690187'
- Now I need to concatenate this with "0"
"0" + str(random.randrange(1000000,10000000))
'06049549'
- So the full code for this script is
print ("0" + str(random.randrange(1000000,10000000)))
- Running the script gives
$ ./phony_id_create.py
05494043
$ ./phony_id_create.py
04385371
String Programs 4 - Creating Passwords
- Web sites frequently ask you to create a password
- The Mac has a feature that suggests a password ...
- and remembers it afterwards
- For some reason this feature did not work on an older Mac I once owned
- I spent a little time investigating the issue
- In the end I decided fixing it would take more time than I had available
- Besides, I could write a Python program to create my own passwords
- I needed to create a list of characters which could be randomly chosen
- I decided to use four groups of characters
- Symbols
- Lowercase letters
- Uppercase letters
- Digits
- Each group of characters would be stored in a tuple
- And these four tuples would be stored inside another tuple
- Characters would be chosen in two steps
- Chose a class of characters
- Chose a character from the class
- In each step I would use randrange with the
length of each list as its argument
- This would randomly select a valid index for the chosen tuple
- Here is the script
PWD_LENGTH = 20
CHARACTERS = (
("!","@", "#", "$", "%", "^", "&", "*"),
("a", "b", "c", "d", "e", "f", "g", "h", "j", "k", "m", "n", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"),
("A", "B", "C", "D", "E", "F", "G", "H", "J", "K", "M", "N", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z"),
("1", "2", "3", "4", "5", "6", "7", "8", "9", "0")
)
def random_char():
tuple_index = random.randrange(4)
tuple = CHARACTERS[tuple_index]
return tuple[random.randrange(len(tuple))]
passwd = ""
for i in range(PWD_LENGTH):
passwd += random_char()
print(passwd)
- Here's what I get when I run the script
$ password_create.py
d*Y&tn%Zk$75G29k*J!N
Confidentiality
Class Exercise
Class Quiz